
When presenting data we’d like to balance two goals:
- Present finding in a clear, unambiguous fashion
- Reflect variation in data and observations that go against the hypothesis
This should be also combined with the notion that Every pixel costs you money.
When highlighting difference between conditions, we can condense data in different ways. For example, we can start with bar graph with error bars. Asterisks signify significance level (p-value) of the difference between two conditions.

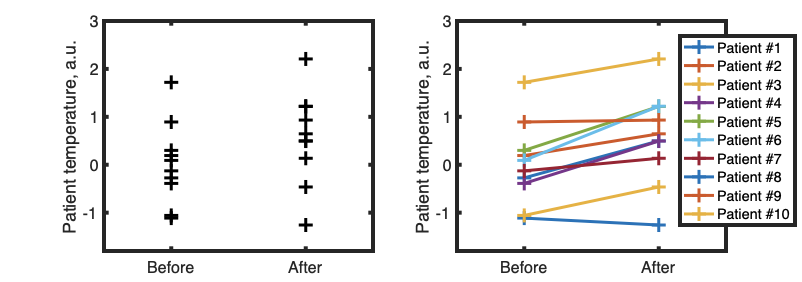
If we know that two conditions are applied to same sample (for example, we measure temperature of patient #1 before and after treatment) then it might be useful to show that using lines:
We sometimes want to show bunch of different stuff on the same plot. Consider this graphics, that overlays multiple fluorescence excitation spectra:

It took me a lot of time to understand it, because it uses two sets of axes for each subplot. That can be an effective tool, and can be easily implemented, say in MATLAB [example one] [example two], but it can also cause confusion. Let’s focus and try to improve single panel:
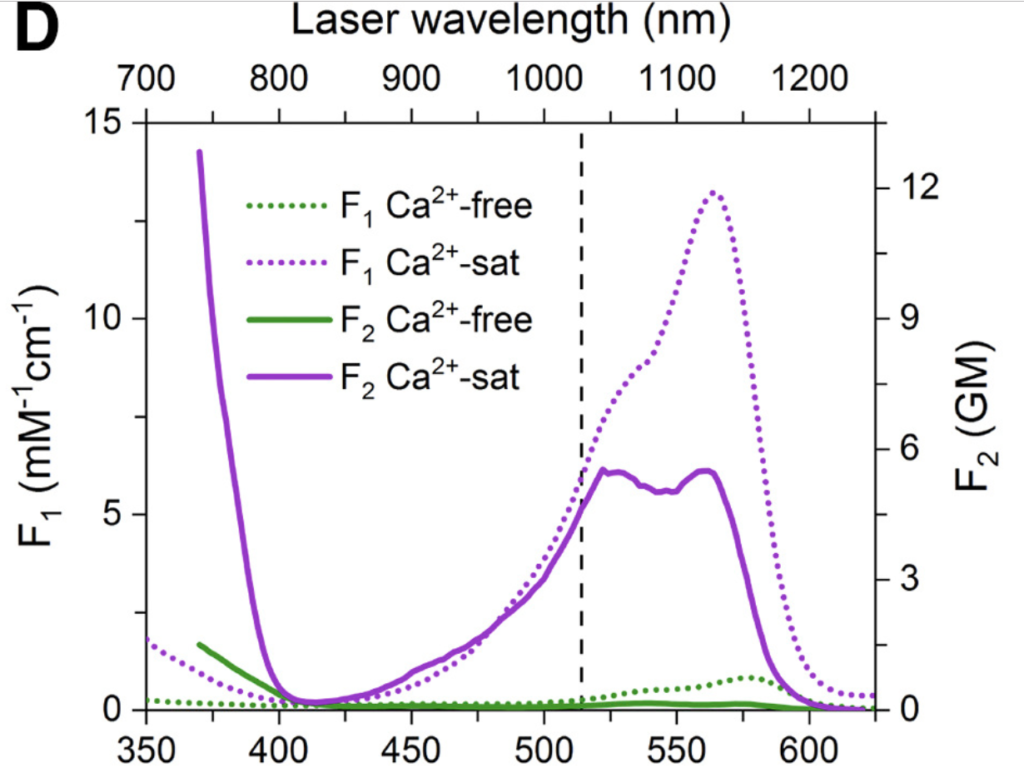
The plot is using color and dashing in order to define 4 different spectra of a calcium-sensitive fluorescent protein. Dashing is used to signify excitation mode (single-photon or two-photon) and color is used to mean presence or absence of calcium. This plot can be improved by flipping this relationship, keeping dashing for calcium amount, and keeping color for illumination mode:
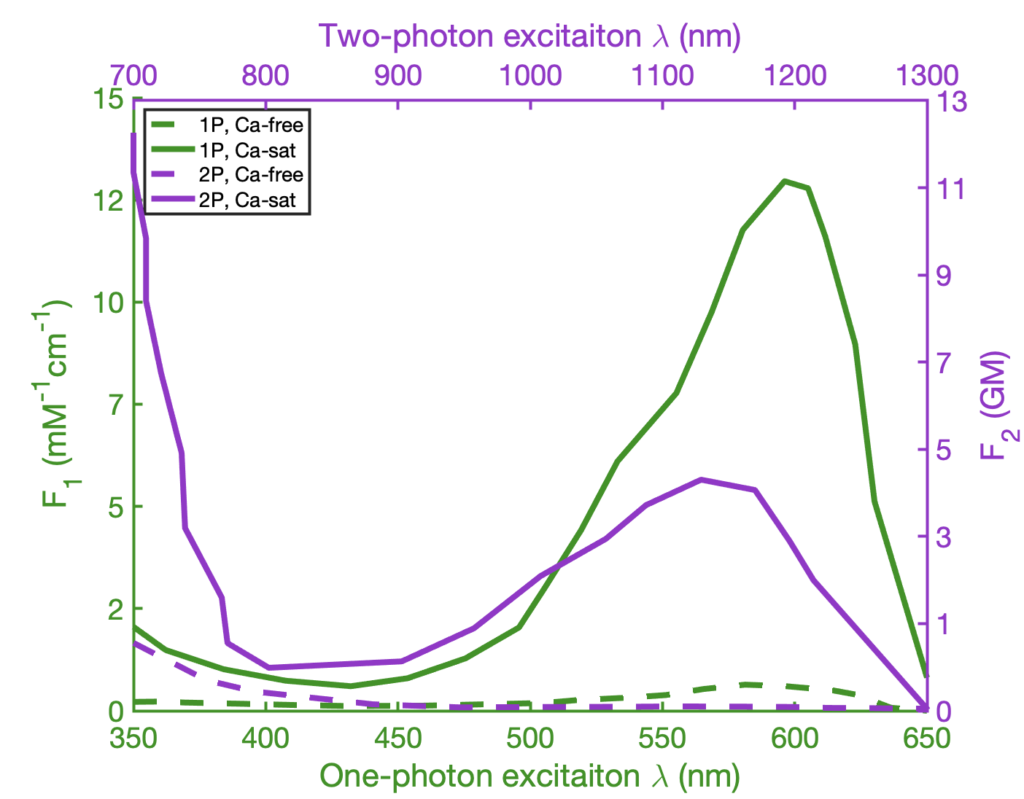
We can see, that least important information (plot of calcium-free fluorescence) is now hidden by dashing, and important stuff (the spectra of excitation) is elevated. We also color-coded the graph lines, as well as axis, so that two graphs can be viewed in the same panel, but also be distinguished visually: the purple line is being read using purple axis, and the green line is being read using green axis.
As final note, few resources on making graphics clear and statistically sound:
- Great work by Edward Tufte, The Visual Display of Quantitative Information
- Axes, ticks and grids, Nature Methods, 2013
- Bar charts and box plots and Visualizing samples with box plots, Nature Methods, 2014
- Show the dots in plots, Nature Biomedical Engineering, 2017